画像に追加の要素を描画する - Inpaint と ControlNet を利用する - Stable Diffusion
画像に追加の要素を描画する手順を紹介します。
概要
元の画像に追加の要素を描画したい場合があります。
この記事では、InpaintとControlNetを利用して画像に追加の要素を描画する手順を紹介します。
要素を追加描画する
事前準備
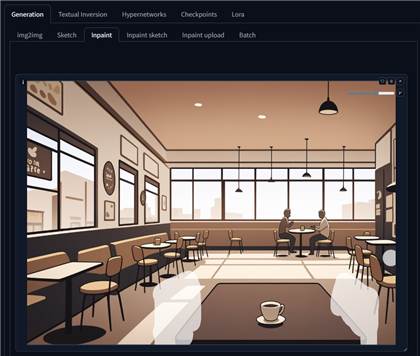
元画像を準備します。下図が元の画像です。

赤丸の位置に椅子を追加したいです。

Inpaintのみでの結果
はじめに単純なInpaintの動作結果を確認します。Stable Diffusion WebUIでimg2imgタブのInpaintのタブに元画像を設定し、
椅子を描画したい位置をドラッグしてInpaintの範囲に設定します。
以下のプロンプトで画像を生成します。
Prompt
Prompt:chair, masterpiece <lora:(絵柄調整用LoRA):1>
Negative prompt: worst quality, low quality
Denoising strength:0.9
Model:aingdiffusionXL v14
結果は下図です。ほとんどの結果で椅子は描画されませんでした。

Inpaint + ControlNet を利用した手順
先の手順では意図した結果になりませんでしたので、ControlNetも利用する方法を実行します。
元画像を修正した下図の画像を用意します。椅子のラフイメージを元画像に追加した画像を用意します。

Stable Diffusion WebUIでimg2imgタブのInpaintのタブに元画像を設定します。
椅子の部分をドラッグしてInpaintの範囲に設定します。
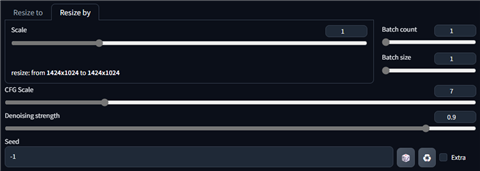
出力サイズは
Scale:1を設定し入力画像と同じサイズとします。Denoising strength:0.9とします。
ControlNetを有効にします。Preprocessorは"lineart_realistic"に設定し、Modelは"controlnet-lora-canny-rank256 [ec2dbbe4]" を設定します。
ControlNetのWeightは0.5を設定しています。Weightは生成結果に応じて変更します。
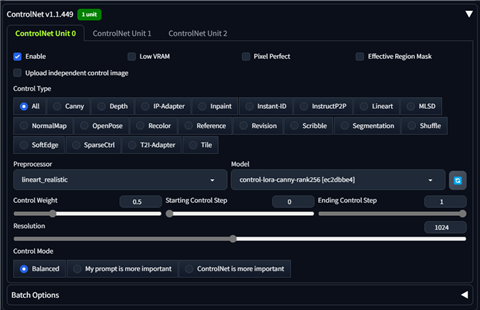
以下のプロンプトで画像を生成します。
Prompt
Prompt:chair, masterpiece <lora:(絵柄調整用LoRA):1>
Negative prompt: worst quality, low quality
Denoising strength:0.9
Model:aingdiffusionXL v14
生成結果画像は下図です。成功率はやや低いですが、元の荒い画像が修正された椅子が描画されている結果も生成できています。

採用した画像が下図です。

キャラクターを追加描画する
キャラクターを追加で描画する方法の紹介です。
先の手順で作成した画像の右下の椅子にキャラクターを座らせて描画したいです。

キャラクターは下図のキャラクターを描画したいです。

事前準備
キャラクターLoRAの作成
キャラクターを描画するためのLoRAを作成します。LoRAの作成手順は
こちらの記事を参照してください。
入力画像の作成
何もない場所にキャラクターを描く場合、AIにとっても手掛かりがないため、ある程度の手がかりを与える必要があります。
ラフでよいのでキャラクターが座った状態のイメージを描画します。下図の画像を準備しました。

Inpaint + ControlNet を利用した手順
img2imgのInpaintを使用します。先に準備した画像を入力画像に設定します。
出力画像のサイズはScale=1とし、入力画像と同じサイズとします。Sampling method は DPM++2M, Schedule type は Automatic, Sampling steps は 20 としています。
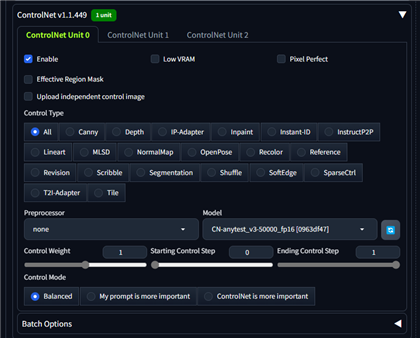
ControlNetを有効にします。今回はControlNetのモデルに、AnyTest (CN-Anytest_v3-50000_fp16 [0963df47])を利用しています。
モデルの詳細は
こちらの記事を参照してください。Preprocessorは"None"としています。
control-lora-canny-rank256 [ec2dbbe4] を利用する方法もありますが、AnyTestを利用した場合は、Preprocessorを使用しないため、色情報をある程度反映できる点を考慮しています。
Control weightは1としていますが、状況によっては値を下げてもよいかもしれません。
画像の生成結果は下図です。

下図の画像を採用しました。ラフで描き足したキャラクターがクリンナップされ、細部の頭のピヨ毛や口の中の塗りわけなどが描画されています。

画像内にキャラクターを追加描画できました。
メモ
LoRAの作成の手間や、手掛かりとなる画像を作成する必要があることを考慮すると、Stable Diffusionを使わずに直接最終イメージを手で描画したほうが、
手間がかからないです。
複数の出力パターンを生成する場合や、背景を変更するなどの手戻りが出た際にはStable Diffusionを利用するメリットが出る可能性もありますが、
現状ではワークフローが確立していないため、何とも言えない状況です。
著者
iPentecのメインデザイナー
Webページ、Webクリエイティブのデザインを担当。PhotoshopやIllustratorの作業もする。
最終更新日: 2024-08-26
作成日: 2024-06-22
