画像の指定した位置にキャラクターを描画する - Stable Diffusion
Stable Diffusionで画像の指定した位置にキャラクターを描画する手順を紹介します。
やりたいこと
下図の画像(背景画像)が用意されています。

この画像の下図の位置(黄色で囲まれた部分)にキャラクターを描画したいです。

inpaint を利用する
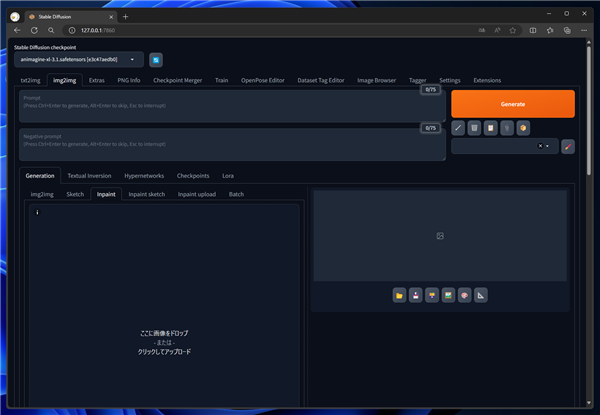
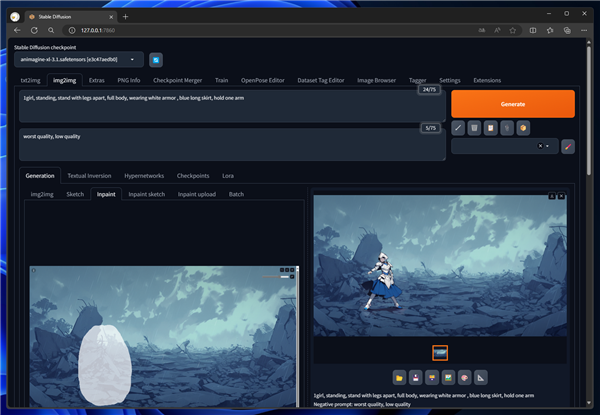
Stable Diffusion WebUI を表示し、[img2img]のタブをクリックして選択します。左側のエリアの[inpaint]のタブをクリックして選択します。
下図の画面が表示されます。
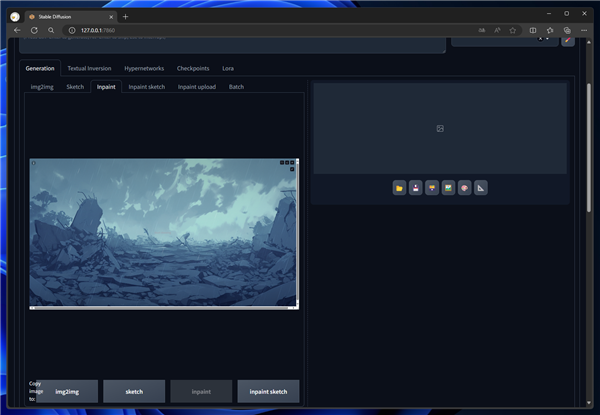
先に紹介した、背景画像をドラッグ&ドロップまたはファイル参照で読み込みます。
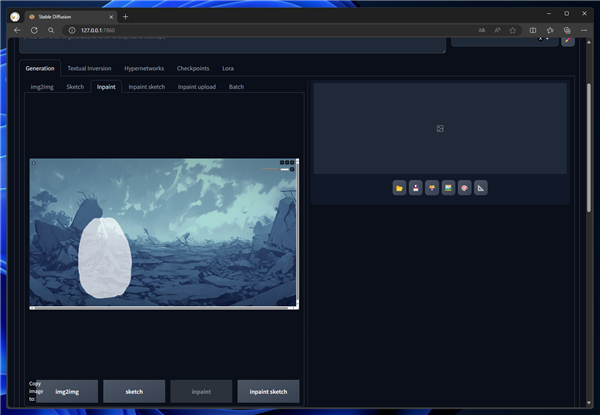
キャラクターを描画したい位置でドラッグしてマスクを作成します。
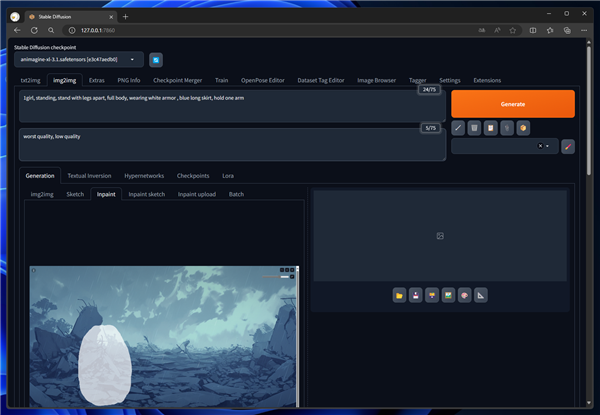
プロンプトを設定します。以下のプロンプトを利用します。
Prompt
Prompt: 1girl, standing, stand with legs apart, full body, wearing white armor , blue long skirt, hold one arm
Negative prompt: worst quality, low quality
画像出力は、[Resize by]のタブを選択し、Scale を
1 に設定します。入力画像と同じサイズでの出力とします。
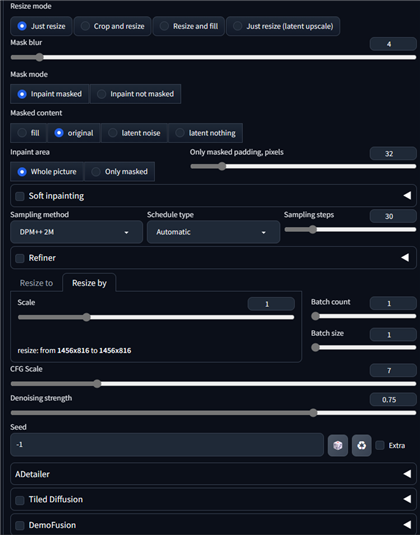
画像を生成します。マスクした領域にキャラクターが描画できました。
生成結果は下図です。キャラクターが描画される場合もありますが、キャラクターが描画されない場合もあります。
また、描画が崩れてしまい、キャラクターの顔はほとんどわかりません。
モブキャラや背景にいるキャラクターであればこの方法で問題ありませんが、メインキャラクターの描画には不向きです。

inpaint+ControlNet を利用する
成功率を上げるため、ControlNetを追加します。下図の下絵を準備します。
入力する背景画像と同じサイズの画像を用意し、キャラクターを描画したい位置に輪郭線を描画しています。

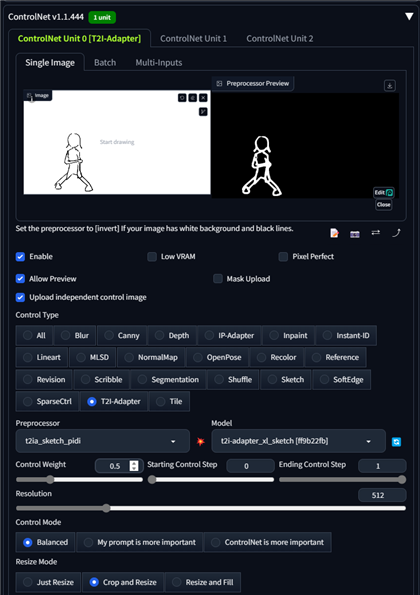
ControlNetの[Enable]チェックボックスをクリックしてチェックをつけます。
[Upload independent control image]のチェックボックスをクリックしてチェックをつけます。
チェックをつけると上部に画像のアップロード枠が表示されますので、ドラッグ&ドロップかファイル選択で、先ほど用意した下絵の画像を読み込みます。
読み込み後、Preprocessor を "t2ia_sketch_pidl" に設定しプリプロセッサを実行します。また、Modelに "t2i-adapter-xl-sketch"を設定します。(モデルハッシュ値 ff9b22fb)
また、Control Weight を0.5に設定します。
下図が画像を読み込み、プリプロセッサの処理を実行し、設定を完了した状態です。
画像を生成します。画像生成結果は下図です。先ほどより成功率が高く、指定したエリアにキャラクターが描画されましたが、
描画がつぶれてしまっている状況は変わりませんでした。
こちらの方法もモブキャラや背景にいるキャラクターであればこの方法で問題ありませんが、メインキャラクターの描画には不向きです。

原因として考えられるのは、指定した領域の解像度が小さすぎるためうまく描画できない可能性があります。
今回入力に用いた背景画像のサイズは、1,456x816 pixelでキャラクターを描画したい領域のサイズは 224x475 pixelのため、SDXLの描画出力の1024よりかなり小さいです。
出力の画像サイズを2倍にして実行結果を確認してみたいところですが、
Scaled by のScale を
2 に設定した場合、画像生成を実行するためには42GBのVRAMが必要なため、実行できませんでした。
RTX 6000 Adaを入手すれば、48GBのVRAMが利用できますが、現状では対処法は無い状況です。
別画像で生成して合成する
先の手順では意図した画像が作成できなかったため、別の方法を検討します。
キャラクターの画像を別途生成し、背景を抜き出してキャラクターのみを背景画像に合成する方法がありそうです。
以下のプロンプトで画像生成します。
Prompt
Prompt: best quality, very aesthetic, 1girl, standing, stand with legs apart, full body, wearing white light armor , blue long skirt, hold one arm, brown boots, dark gray background
Negative prompt: worst quality, low quality, helmet
生成結果は下図です。生成はできましたが、想定イメージと違います。

ControlNetを有効にし、Scribbleで下図の画像を入力して生成します。
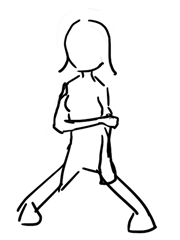
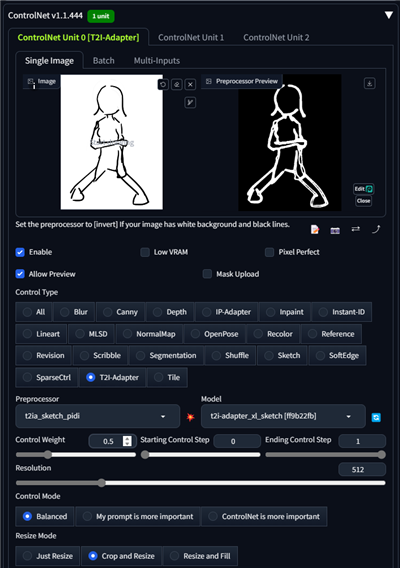
プロンプトは以下とします。
Prompt
Prompt: best quality, very aesthetic, (anime style:0.2), 1girl, standing, (legs apart:1.2), full body, from just front, wearing white light armor , blue long skirt, hold one arm, brown boots, dark gray background
Negative prompt: worst quality, low quality, helmet
生成結果は下図です。先の結果とあまり変わり映えがしません。

ControlNetをOffにしてプロンプトを検討します。試行錯誤の後、以下のプロンプトになりました。
Prompt
Prompt: best quality, very aesthetic,1girl, 14yo, standing, from front just, blue skirt, gray shirt, full body, bleeding arm, hold right one arm, legs apart, wearing white light armor ,gray background
Negative prompt: worst quality, low quality, helmet
生成結果は下図です。想定イメージに近くなりました。

OpenPoseを導入します。OpenPose Editorで下図のポーズを作成します。
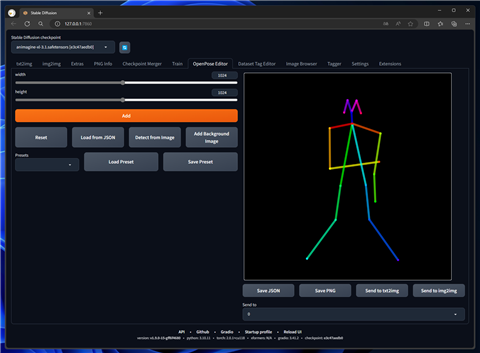
[Sand to txt2img]ボタンをクリックし、txt2imgのControlNetの入力に設定します。
Preprocessorは"none"、Modelは"thibaud_OpenPoseXL2" (モデルハッシュ
f4251cb4) を指定します。Control Weightは0.75に設定します。
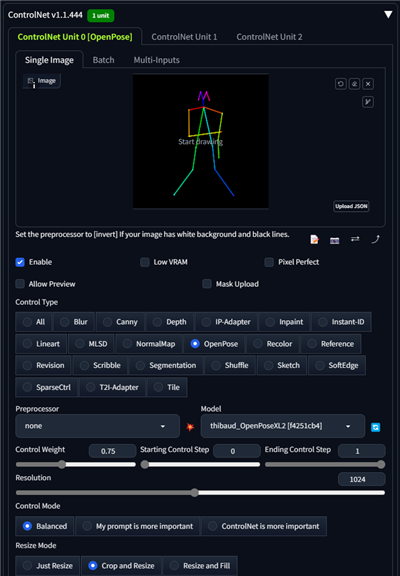
プロンプトを下記に変更します。
Prompt
Prompt: best quality, very aesthetic,1girl, 14yo, black hair, standing,look at forward, leaning forward, from front just, blue skirt, gray shirt, full body, bleeding arm, (hold one arm:1.2), legs apart, wearing white light armor ,gray boots, gray background
Negative prompt: worst quality, low quality, helmet
画像を生成します。生成結果は下図になります。

こちらのイメージを採用としました。ABG Removerで背景を除去します。
ABG Removerについては
こちらの記事を参照してください。

Photoshopで画像を合成します。カラーを調整して背景画像と合わせます。
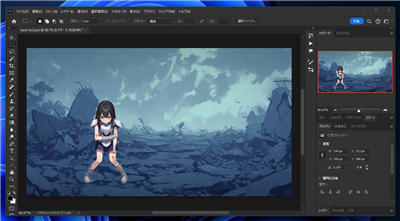
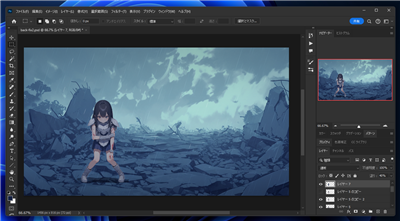
背景とキャラクターを合成した画像が下図です。

Tiled Diffusionでアップスケールします。VRAM不足のため、2倍にはアップスケールできないため、1.75倍にアップスケールします。
画像が大きく変化しないようDenoising strengthを
0.2に設定します。
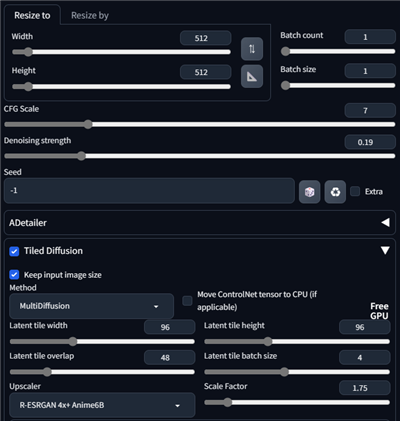
アップスケールした画像が以下です。

著者
iPentecのメインデザイナー
Webページ、Webクリエイティブのデザインを担当。PhotoshopやIllustratorの作業もする。
