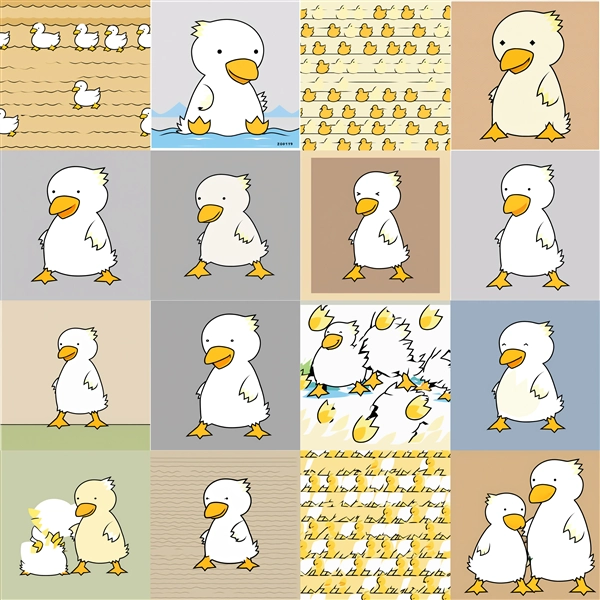
conv_dim の違いによるLoRA (C3Lier) の出力の違い (SDXL版) - Stable Diffusion
LoRA(C3Lier)のconv_dimの違いで出力画像にどのような変化があるかを確認します。
LoRAの学習
学習データ
こちらのページの「学習データ (テスト用 ミニ v4)」を利用します。
パラメーター
SDXLで学習します。
accelerate launch --num_cpu_threads_per_process 1 sdxl_train_network.py --config_file=D:\data\c3lier-toricchi-xl\config.toml
[model_arguments]
pretrained_model_name_or_path = "D:\\data\\model\\sdXL_v10.safetensors"
[additional_network_arguments]
network_train_unet_only = true
cache_text_encoder_outputs = true
network_module = "networks.lora"
network_args = [ "conv_dim=16", "conv_alpha=1" ] #conv_dim の値を変化させます。(4,8,16)
[optimizer_arguments]
optimizer_type = "AdamW"
learning_rate = 1e-4
network_dim = 16
network_alpha = 1
[dataset_arguments]
dataset_config = "D:\\data\\c3lier-toricchi-xl\\dataset.toml"
cache_latents = true
[training_arguments]
output_dir = "D:\\data\\c3lier-toricchi-xl\\output"
output_name = "toricchi"
save_every_n_epochs = 100
save_model_as = "safetensors"
max_train_steps = 6000
xformers = true
mixed_precision= "bf16"
gradient_checkpointing = true
persistent_data_loader_workers = true
keep_tokens = 1
[dreambooth_arguments]
prior_loss_weight = 1.0
[general]
enable_bucket = true
[[datasets]]
resolution = 1024
batch_size = 1
[[datasets.subsets]]
image_dir = 'D:\data\c3lier-toricchi-xl\toricchi'
caption_extension = '.txt'
num_repeats = 1
学習
上記の設定で学習します。
プロンプト
次の3つのプロンプトで学習回数の違いによる生成画像の結果を確認します。
Prompt1
Prompt: <lora:toricchi-000n00:1> toricchi, duck
Negative prompt: worst quality, low quality
Prompt2
Prompt: <lora:toricchi-000n00:1> toricchi, duck,1 girl, sunflower field background, blue sky
Negative prompt: worst quality, low quality
Prompt3
Prompt: <lora:toricchi-000n00:1> toricchi, duck, cyberpunk, dark city, battle
Negative prompt: worst quality, low quality
生成結果
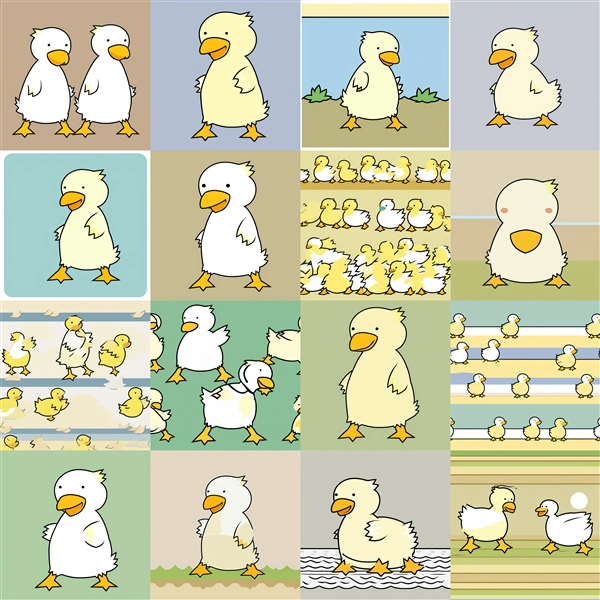
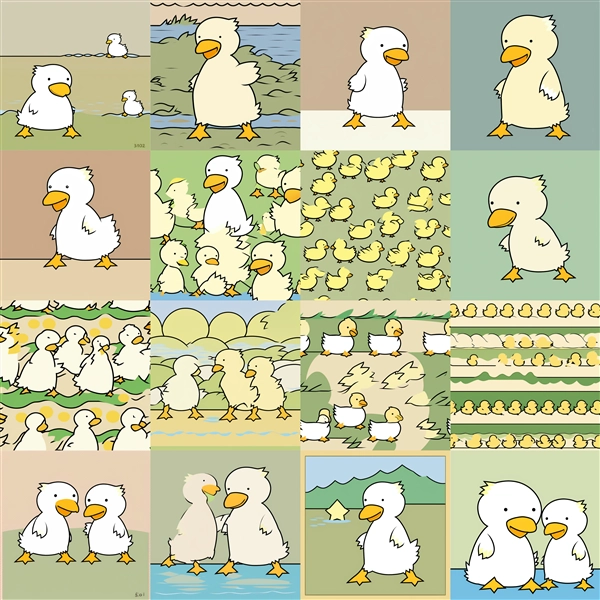
Dim=16 : conv_dim=4
Epoch100:step700
Epoch200:step1,400
Epoch300:step2,100
Epoch400:step2,800
Epoch500:step3,500
Epoch600:step4,200
Epoch700:step4,900
Epoch800:step5,600
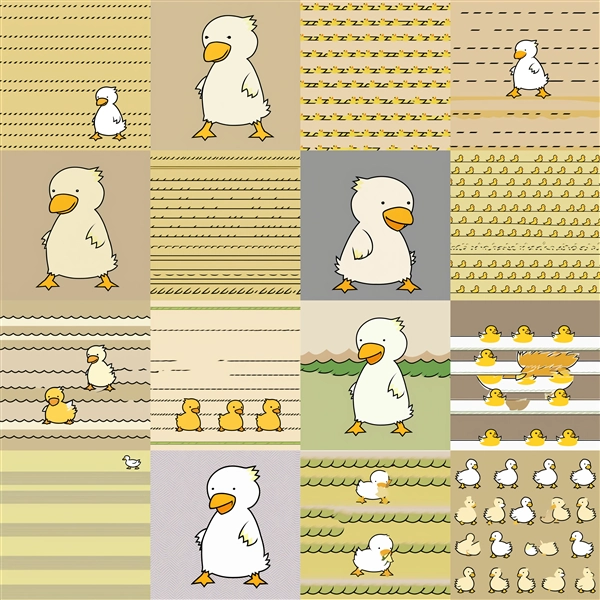
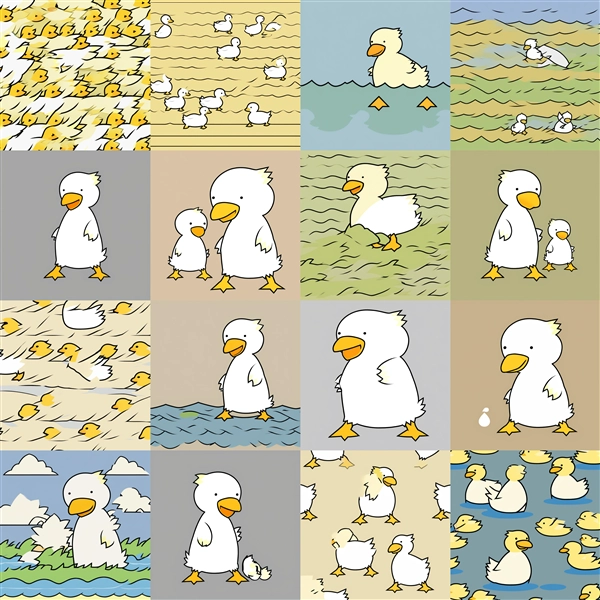
Dim=16 : conv_dim=8
Epoch100:step700
Epoch200:step1,400
Epoch300:step2,100
Epoch400:step2,800
Epoch500:step3,500
Epoch600:step4,200
Epoch700:step4,900
Epoch800:step5,600
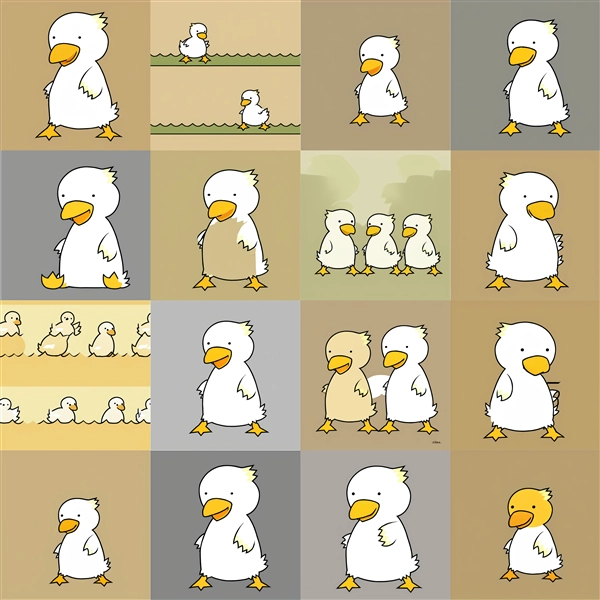
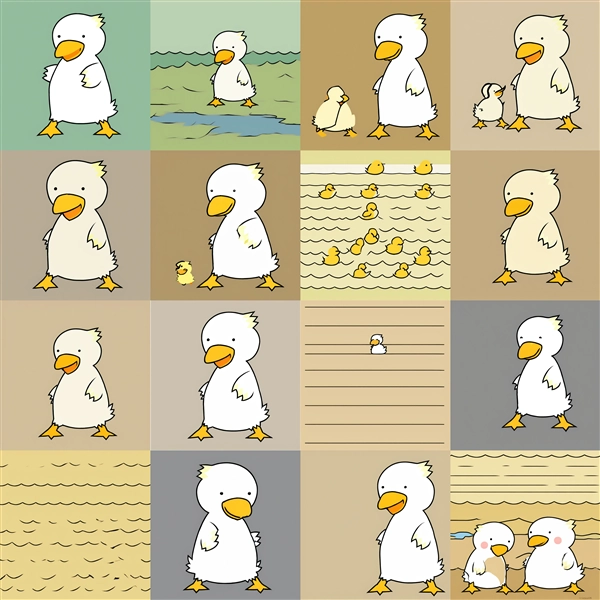
Dim=16 : conv_dim=16
Epoch100:step700
Epoch200:step1,400
Epoch300:step2,100
Epoch400:step2,800
Epoch500:step3,500
Epoch600:step4,200
Epoch700:step4,900
Epoch800:step5,600
評価・所感
Epoch100~200ではキャラクター単体の生成の場合に、模様状の画像が表示される場合があります。また、conv_dimが低い場合で学習回数が多い場合も
模様状の画像が出力されます。conv_dimが高くなると、学習回数が多い場合での崩れが減る傾向です。
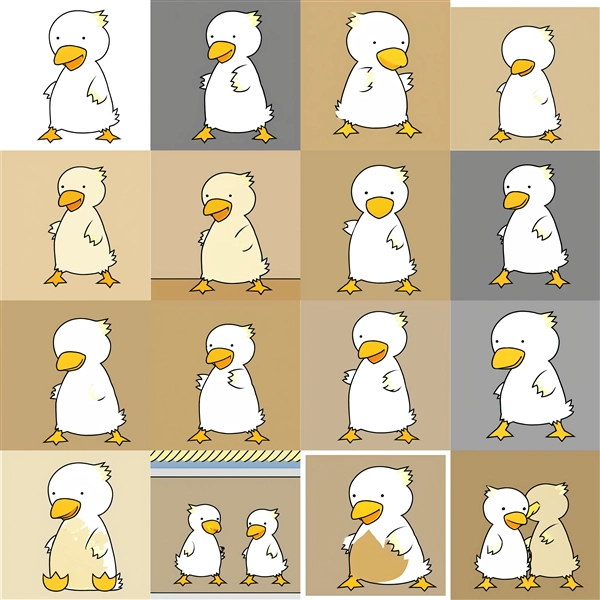
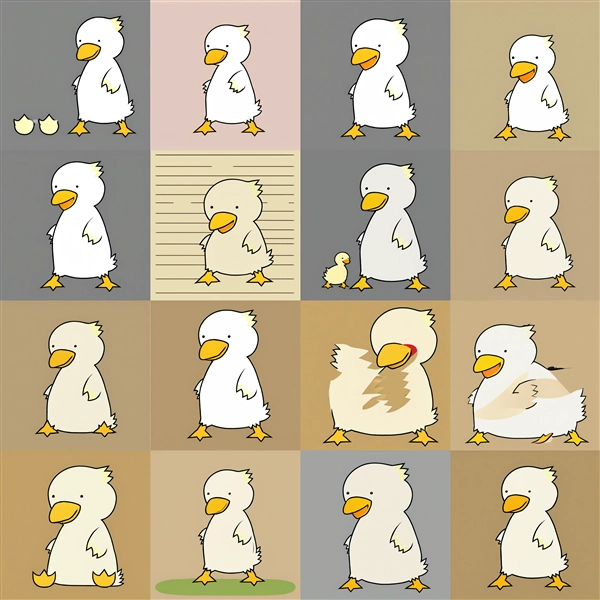
一方で、Prompt3の背景は、conv_dimの値が4の場合はEpoch300あたりから、conv_dimの値が16の場合は、Epoch 400 背景が描画されず、
無地の背景が描画されるケースが目立ちます。
Epochが600以上の場合、キャラクターが学習画像を反映されて出力されますが、Prompt3の背景が無地になってしまう傾向です。
今回の学習データでは、C3Lierより通常のLoRAのほうが結果が良好な印象があります。
著者
iPentecのメインデザイナー
Webページ、Webクリエイティブのデザインを担当。PhotoshopやIllustratorの作業もする。